
Open-source deep learning framework simplifies creation of modern AI applications, adhering to GitFlow for branching and Semantic Versioning for release management.


![]()
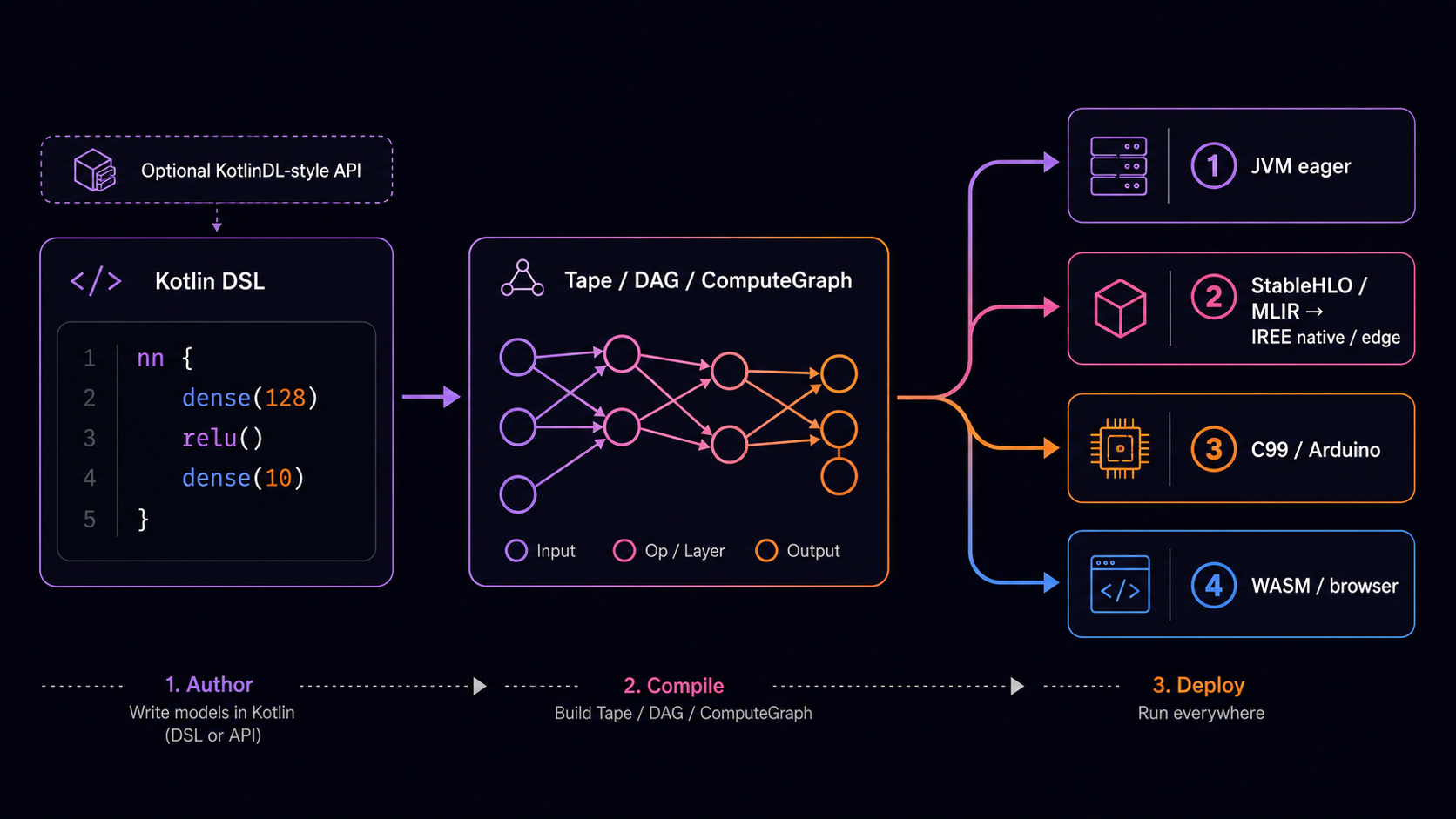
Click the diagram for the full architecture reference, or read the short ARCHITECTURE.md.
SKaiNET is a Kotlin Multiplatform AI framework. New here? Choose the path that matches what you want to try first.
| Goal | Start here | Time |
|---|---|---|
| Run tensor operations | Quickstart (below) | 2–5 min |
| Build and train a neural net | Hello Neural Net (below) | 5 min |
| Run a local GGUF model | SKaiNET Transformers starter | 5 min after model setup |
| Export a secure MCU bundle | Minerva getting started | 10 min without firmware flashing |
Working in Java? SKaiNET ships first-class Java support — see the Java getting-started guide.
Use the version shown in this README as the source of truth for first-run snippets. If another page shows a different version, please open an issue or PR.
Add the core dependencies (Gradle Kotlin DSL):
dependencies {
// Recommended: import the umbrella BOM and drop versions on the engine modules.
implementation(platform("sk.ainet:skainet-bom:0.37.0"))
implementation("sk.ainet.core:skainet-lang-core")
implementation("sk.ainet.core:skainet-backend-cpu")
}val model = nn {
input(28 * 28)
dense(out = 128)
relu()
dense(out = 10)
}val a = tensor(shape(2, 2)) { float(1f, 2f, 3f, 4f) }
val b = tensor(shape(2, 2)) { float(5f, 6f, 7f, 8f) }
val c = a matMul b
val d = c.relu()// Recommended: streaming reader — memory-efficient, supports quantized types
val source = JvmRandomAccessSource.open("model.gguf")
StreamingGGUFReader.open(source).use { reader ->
println("Tensors: ${reader.tensorCount}")
// Load specific tensor on demand (no whole-file loading)
val bytes = reader.loadTensor("token_embd.weight")
// Or get a TensorStorage descriptor with encoding/placement metadata
val storage = reader.loadTensorStorage("token_embd.weight")
}More examples: SKaiNET-examples | SKaiNET-notebook
SKaiNET is a modular ecosystem. While this repository contains the core engine, specialized high-level libraries are maintained in standalone repositories:
| Project | Description |
|---|---|
| SKaiNET-transformers | Pre-built transformer architectures and layers |
| SKaiNET-examples | Sample projects and integration demos |
| Goal | Start here |
|---|---|
| Examples and sample projects | SKaiNET-examples |
| Interactive notebooks | SKaiNET-notebook |
| Eager backends & kernels (what runs where) | Backends & kernels mindmap |
| Design proposals and long-lived API decisions | SKEEP proposals |
Small fixes can go straight through the normal contribution flow described in CONTRIBUTING.md and GITFLOW.adoc.
Use a SKEEP when a change affects public APIs, DSL syntax, tensor semantics,
compiler/runtime integration, storage behavior, compatibility policy, or other
decisions that need a durable design record. SKEEP files live under
docs/modules/skeep/pages/ and use three-digit numbering, starting with
001.
SKaiNET ships an official Phoronix-Test-Suite-compatible benchmark
program for the compute engine. See the
methodology and replay docs,
the release manifest, and the
CI workflow. Smoke runs fire
on every PR via ubuntu-latest; full publishable runs fire on a
self-hosted Linux x86 runner on release.
Quick local replay:
./gradlew :skainet-backends:benchmarks:jvm-cpu-publish:shadowJar
./scripts/run_engine_smoke.shSKaiNET is built around one path: a model is defined once in the Kotlin DSL, then either compiled or executed eagerly — without rewriting it.
nn { } / dag { }).ComputeGraph.ComputeGraph through one of several
sibling code-generation backends, each emitting code for a different target
from the same graph:
HloGenerator) → IREE-compilable, for native / edge /
accelerator targets and the wider MLIR ecosystem.StableHLO/MLIR is therefore one code-generation backend among siblings — the IREE/native path next to the C99/Arduino and Minerva MCU paths — not a separate pipeline.
flowchart LR
DSL["Model — Kotlin DSL"] --> Graph["Tape / DAG (ComputeGraph)"]
Graph --> Eager["Eager backend (JVM, …)"]
Graph -->|code generation| HLO["StableHLO / MLIR"]
Graph -->|code generation| C99["Arduino / C99"]
Graph -->|code generation| Minerva["Minerva"]
HLO --> Native["IREE → native / edge / accelerator"]
C99 --> MCU["Microcontroller"]
Minerva --> SecMCU["Secure-MCU bundle"]The same DSL model feeds every path: eager execution for development and JVM deployment, and the code-generation backends — StableHLO/MLIR (→ IREE), Arduino/C99, and Minerva — as sibling alternatives for native, edge, and secure-MCU targets.
SKaiNET now includes a Minerva export backend for secure MCU deployment. It is a sibling to StableHLO and Arduino/C99 export: it starts from a supported ComputeGraph, lowers static MLPs to a Minerva compiler input, invokes libminerva when configured, and packages generated weights, host fixtures, firmware skeletons, and a fingerprinted manifest.json.
Start here:
Runnable examples:
./gradlew :skainet-compile:skainet-compile-minerva:runMinervaSecureMcuExamples
./gradlew :skainet-compile:skainet-compile-minerva:runMinervaSecureMcuExamples \
-Pminerva.example=sensor-classifiersafe-lowbit, balanced, experimental-max. See TurboQuantUsage for integration guide.nn { input(); dense(); relu(); dense() }
dag { } for ResNet, YOLO-style architecturesfile://, https://, hf+https://, and hf://...
.jsonl, .ndjson)val raw = JvmDataSourceResolver().rawDataset {
from("hf://datasets/org/repo@main/train.jsonl")
format(DataFormat.JSON_LINES)
cachePolicy(CachePolicy.Use)
}
val withoutLabel = dataPipeline<RawDataset>()
.stage(
dataTransformer(
name = "drop-label",
outputSchema = { schema -> DataSchema(schema.columns - "label") }
) { dataset ->
val columns = dataset.schema.columns - "label"
dataset.copy(
schema = DataSchema(columns),
rows = dataset.rows.map { row ->
RawDataRow(row.values.filterKeys { key -> key in columns })
}
)
}
)
.execute(raw)HloGenerator
Lstm layer — single-layer, batch-first LSTM built from existing primitives only (no new TensorOps op, traces to StableHLO without a dedicated converter), with torch.nn.LSTM-compatible gate order and an explicit caller-owned LstmState + step() API for transducer prediction networks.Dropout now performs real inverted dropout under a training-phase context (it was an identity placeholder), optimizers expose a mutable lr plus a linearWarmupCosineDecay LR schedule, Linear supports bias-less projections (nn.Linear(bias=False) equivalent) and is open for LoRA-style adapters.scaledDotProductAttention at its default scale multiplied every score by zero on the CPU backend, collapsing softmax to a uniform average; it now resolves to 1/sqrt(headDim) as documented.CrossEntropyLoss no longer detaches the tape (gradients reached the predictions in neither target path), and softmax/logSoftmax/variance backward now work for rank ≥ 3.skainet-io-core and skainet-io-safetensors gain androidNative targets (arm64 and arm32).allTests split into parallel per-target jobs to end OOM flakes.permute replay fix (ComputeGraphExecutor) — a traced permute(t, axes) now replays with its recorded axes instead of being dispatched as a plain last-two-dims transpose.REUSE.toml + LICENSES/, a CI compliance workflow, and a REUSE status badge.See CHANGELOG.md for details and the full release history.
We love contributions! Whether it's a new operator, documentation, or a bug fix:
Browse the full codebase documentation on DeepWiki.
Lstm layer (#824), Dropout masking (#867), LR schedules (#866), optional/open Linear (#870, #875), SDPA scale fix (#880), autograd fixes (#877), argMax DAG spec (#878), tokenizer + gather fixes (#879), Android native IO targets (#836, #842, #845)MIT — see LICENCE.
![]()
Click the diagram for the full architecture reference, or read the short ARCHITECTURE.md.
SKaiNET is a Kotlin Multiplatform AI framework. New here? Choose the path that matches what you want to try first.
| Goal | Start here | Time |
|---|---|---|
| Run tensor operations | Quickstart (below) | 2–5 min |
| Build and train a neural net | Hello Neural Net (below) | 5 min |
| Run a local GGUF model | SKaiNET Transformers starter | 5 min after model setup |
| Export a secure MCU bundle | Minerva getting started | 10 min without firmware flashing |
Working in Java? SKaiNET ships first-class Java support — see the Java getting-started guide.
Use the version shown in this README as the source of truth for first-run snippets. If another page shows a different version, please open an issue or PR.
Add the core dependencies (Gradle Kotlin DSL):
dependencies {
// Recommended: import the umbrella BOM and drop versions on the engine modules.
implementation(platform("sk.ainet:skainet-bom:0.37.0"))
implementation("sk.ainet.core:skainet-lang-core")
implementation("sk.ainet.core:skainet-backend-cpu")
}val model = nn {
input(28 * 28)
dense(out = 128)
relu()
dense(out = 10)
}val a = tensor(shape(2, 2)) { float(1f, 2f, 3f, 4f) }
val b = tensor(shape(2, 2)) { float(5f, 6f, 7f, 8f) }
val c = a matMul b
val d = c.relu()// Recommended: streaming reader — memory-efficient, supports quantized types
val source = JvmRandomAccessSource.open("model.gguf")
StreamingGGUFReader.open(source).use { reader ->
println("Tensors: ${reader.tensorCount}")
// Load specific tensor on demand (no whole-file loading)
val bytes = reader.loadTensor("token_embd.weight")
// Or get a TensorStorage descriptor with encoding/placement metadata
val storage = reader.loadTensorStorage("token_embd.weight")
}More examples: SKaiNET-examples | SKaiNET-notebook
SKaiNET is a modular ecosystem. While this repository contains the core engine, specialized high-level libraries are maintained in standalone repositories:
| Project | Description |
|---|---|
| SKaiNET-transformers | Pre-built transformer architectures and layers |
| SKaiNET-examples | Sample projects and integration demos |
| Goal | Start here |
|---|---|
| Examples and sample projects | SKaiNET-examples |
| Interactive notebooks | SKaiNET-notebook |
| Eager backends & kernels (what runs where) | Backends & kernels mindmap |
| Design proposals and long-lived API decisions | SKEEP proposals |
Small fixes can go straight through the normal contribution flow described in CONTRIBUTING.md and GITFLOW.adoc.
Use a SKEEP when a change affects public APIs, DSL syntax, tensor semantics,
compiler/runtime integration, storage behavior, compatibility policy, or other
decisions that need a durable design record. SKEEP files live under
docs/modules/skeep/pages/ and use three-digit numbering, starting with
001.
SKaiNET ships an official Phoronix-Test-Suite-compatible benchmark
program for the compute engine. See the
methodology and replay docs,
the release manifest, and the
CI workflow. Smoke runs fire
on every PR via ubuntu-latest; full publishable runs fire on a
self-hosted Linux x86 runner on release.
Quick local replay:
./gradlew :skainet-backends:benchmarks:jvm-cpu-publish:shadowJar
./scripts/run_engine_smoke.shSKaiNET is built around one path: a model is defined once in the Kotlin DSL, then either compiled or executed eagerly — without rewriting it.
nn { } / dag { }).ComputeGraph.ComputeGraph through one of several
sibling code-generation backends, each emitting code for a different target
from the same graph:
HloGenerator) → IREE-compilable, for native / edge /
accelerator targets and the wider MLIR ecosystem.StableHLO/MLIR is therefore one code-generation backend among siblings — the IREE/native path next to the C99/Arduino and Minerva MCU paths — not a separate pipeline.
flowchart LR
DSL["Model — Kotlin DSL"] --> Graph["Tape / DAG (ComputeGraph)"]
Graph --> Eager["Eager backend (JVM, …)"]
Graph -->|code generation| HLO["StableHLO / MLIR"]
Graph -->|code generation| C99["Arduino / C99"]
Graph -->|code generation| Minerva["Minerva"]
HLO --> Native["IREE → native / edge / accelerator"]
C99 --> MCU["Microcontroller"]
Minerva --> SecMCU["Secure-MCU bundle"]The same DSL model feeds every path: eager execution for development and JVM deployment, and the code-generation backends — StableHLO/MLIR (→ IREE), Arduino/C99, and Minerva — as sibling alternatives for native, edge, and secure-MCU targets.
SKaiNET now includes a Minerva export backend for secure MCU deployment. It is a sibling to StableHLO and Arduino/C99 export: it starts from a supported ComputeGraph, lowers static MLPs to a Minerva compiler input, invokes libminerva when configured, and packages generated weights, host fixtures, firmware skeletons, and a fingerprinted manifest.json.
Start here:
Runnable examples:
./gradlew :skainet-compile:skainet-compile-minerva:runMinervaSecureMcuExamples
./gradlew :skainet-compile:skainet-compile-minerva:runMinervaSecureMcuExamples \
-Pminerva.example=sensor-classifiersafe-lowbit, balanced, experimental-max. See TurboQuantUsage for integration guide.nn { input(); dense(); relu(); dense() }
dag { } for ResNet, YOLO-style architecturesfile://, https://, hf+https://, and hf://...
.jsonl, .ndjson)val raw = JvmDataSourceResolver().rawDataset {
from("hf://datasets/org/repo@main/train.jsonl")
format(DataFormat.JSON_LINES)
cachePolicy(CachePolicy.Use)
}
val withoutLabel = dataPipeline<RawDataset>()
.stage(
dataTransformer(
name = "drop-label",
outputSchema = { schema -> DataSchema(schema.columns - "label") }
) { dataset ->
val columns = dataset.schema.columns - "label"
dataset.copy(
schema = DataSchema(columns),
rows = dataset.rows.map { row ->
RawDataRow(row.values.filterKeys { key -> key in columns })
}
)
}
)
.execute(raw)HloGenerator
Lstm layer — single-layer, batch-first LSTM built from existing primitives only (no new TensorOps op, traces to StableHLO without a dedicated converter), with torch.nn.LSTM-compatible gate order and an explicit caller-owned LstmState + step() API for transducer prediction networks.Dropout now performs real inverted dropout under a training-phase context (it was an identity placeholder), optimizers expose a mutable lr plus a linearWarmupCosineDecay LR schedule, Linear supports bias-less projections (nn.Linear(bias=False) equivalent) and is open for LoRA-style adapters.scaledDotProductAttention at its default scale multiplied every score by zero on the CPU backend, collapsing softmax to a uniform average; it now resolves to 1/sqrt(headDim) as documented.CrossEntropyLoss no longer detaches the tape (gradients reached the predictions in neither target path), and softmax/logSoftmax/variance backward now work for rank ≥ 3.skainet-io-core and skainet-io-safetensors gain androidNative targets (arm64 and arm32).allTests split into parallel per-target jobs to end OOM flakes.permute replay fix (ComputeGraphExecutor) — a traced permute(t, axes) now replays with its recorded axes instead of being dispatched as a plain last-two-dims transpose.REUSE.toml + LICENSES/, a CI compliance workflow, and a REUSE status badge.See CHANGELOG.md for details and the full release history.
We love contributions! Whether it's a new operator, documentation, or a bug fix:
Browse the full codebase documentation on DeepWiki.
Lstm layer (#824), Dropout masking (#867), LR schedules (#866), optional/open Linear (#870, #875), SDPA scale fix (#880), autograd fixes (#877), argMax DAG spec (#878), tokenizer + gather fixes (#879), Android native IO targets (#836, #842, #845)MIT — see LICENCE.