Uncompressed, dynamically resizable bitset supports efficient bit operations like enumeration, setting, clearing, and logical operations without allocation overhead. Offers enhanced functionality and performance optimizations.
Uncompressed, dynamically resizeable bitset, similar to java.util.BitSet.
Long emulation in JSBased on Adrian Papari initial implementation and has been enhanced to add new functionality and modern Kotlin support:
first, last, clear, invert and more)BitVector and MutableBitVector
countOneBits, countLeadingZeroBits
implementation("io.github.adokky:bitvector:0.9")val bv: BitVector = bitsOf(1, 2, 56, 64, 128, 129, 130, 131, 420)val bv = MutableBitVector()
bv[142] = true // or bv.set(142)
assert(142 in bv)
bv.unset(142) // or bv[142] = false
assert(142 !in bv)val a = bitsOf(0, 1, 2, 3, 120, 130)
val b = bitsOf(0, 1, 2, 120, 121, 122, 123, 130)
assert(a.and(b) == bitsOf(0, 1, 2, 120, 130))// 1, 4 contained in other
bitsOf(1, 4) in bitsOf(0, 1, 4, 5, 6) bitsOf(*bits).forEachBit { println("bit $it says hi") }// can be combined with filter/map etc
bitsOf(*bits).forEach { println("bit $it says hi") }Mapping true bit positions into integers, inserting each into an IntBag (thin wrapper around int[]).
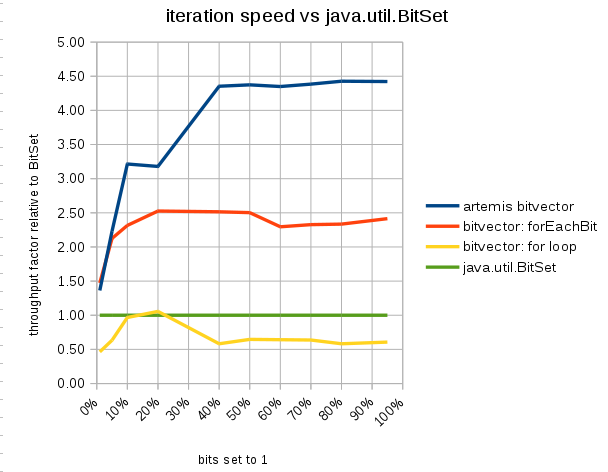
artemis-odb's BitVector was the basis for this implementation. The benchmark setup favors the artemis implementation, as it provides an optimized toIntBag method: it serves as a reference for best possible performance.
See jmh-logs for the full logs.
Discrepancy to artemis BitVector is unwelcome. The implementation is for the most part the same, except that this implementation uses int for words, instead of long. 4 or 8 byte words did not have a significant impact on performance.
The for-loop performs poorly due to all the Integer boxing, extra indirection and allocation, compared to forEachBit.
java.util.BitSet suffers from not having a way of enumerating all bits at once, instead relying on repeatedly calling nextSetBit.
Uncompressed, dynamically resizeable bitset, similar to java.util.BitSet.
Long emulation in JSBased on Adrian Papari initial implementation and has been enhanced to add new functionality and modern Kotlin support:
first, last, clear, invert and more)BitVector and MutableBitVector
countOneBits, countLeadingZeroBits
implementation("io.github.adokky:bitvector:0.9")val bv: BitVector = bitsOf(1, 2, 56, 64, 128, 129, 130, 131, 420)val bv = MutableBitVector()
bv[142] = true // or bv.set(142)
assert(142 in bv)
bv.unset(142) // or bv[142] = false
assert(142 !in bv)val a = bitsOf(0, 1, 2, 3, 120, 130)
val b = bitsOf(0, 1, 2, 120, 121, 122, 123, 130)
assert(a.and(b) == bitsOf(0, 1, 2, 120, 130))// 1, 4 contained in other
bitsOf(1, 4) in bitsOf(0, 1, 4, 5, 6) bitsOf(*bits).forEachBit { println("bit $it says hi") }// can be combined with filter/map etc
bitsOf(*bits).forEach { println("bit $it says hi") }Mapping true bit positions into integers, inserting each into an IntBag (thin wrapper around int[]).
artemis-odb's BitVector was the basis for this implementation. The benchmark setup favors the artemis implementation, as it provides an optimized toIntBag method: it serves as a reference for best possible performance.
See jmh-logs for the full logs.
Discrepancy to artemis BitVector is unwelcome. The implementation is for the most part the same, except that this implementation uses int for words, instead of long. 4 or 8 byte words did not have a significant impact on performance.
The for-loop performs poorly due to all the Integer boxing, extra indirection and allocation, compared to forEachBit.
java.util.BitSet suffers from not having a way of enumerating all bits at once, instead relying on repeatedly calling nextSetBit.