
High-performance, asynchronous, lock-free in-memory fuzzy search engine optimized for instant typeahead; L2-normalized sparse vectors, O(1) lookups, fuzzy prefixes, skip-grams and typo‑resilient scoring.

A high-performance, asynchronous, and lock-free in-memory fuzzy search engine designed specifically for Kotlin Multiplatform (KMP).
Unlike standard search algorithms that fail during real-time typing, typeahead-kmp is built to understand the "Blind
Continuation" phenomenon—where users make an early typo but intuitively continue typing the rest of the word
correctly. It also supports multi-word queries across documents of any length—from short labels to long
descriptions—using a tokenized two-stage retrieval architecture with Geometric Mean Scoring, Exponential Proximity
Decay for adjacency awareness, and BM25-inspired length normalization.
Powered by a custom L2-Normalized Sparse Vector Space algorithm, a Flyweight Vocabulary Cache, an Inverted
Index, and immutable state management, it acts as a highly optimized, local vector database. Each query token is
independently matched against the vocabulary and scored against every document token, so searching for "dark knight"
across thousands of movie descriptions works just as naturally as searching for a single word like "batman". The engine
yields a normalized similarity score in [0.0, 1.0] while gracefully handling skipped characters, swapped letters,
and phonetic typos.
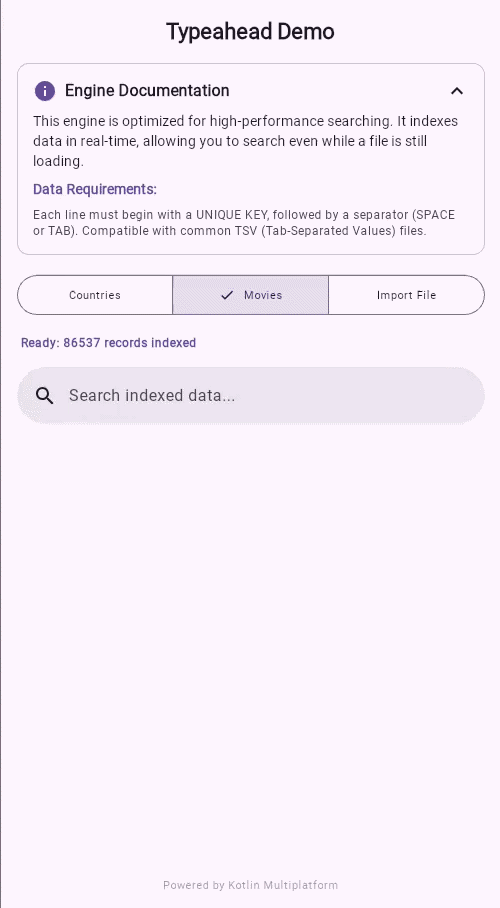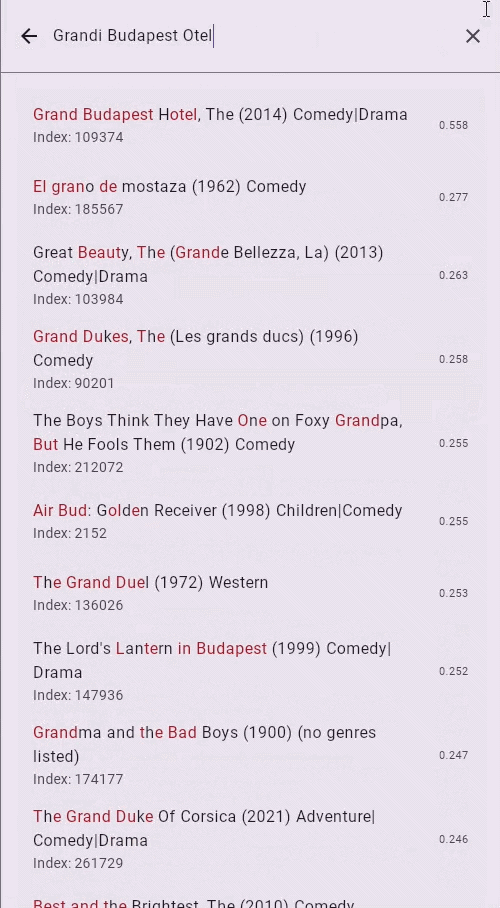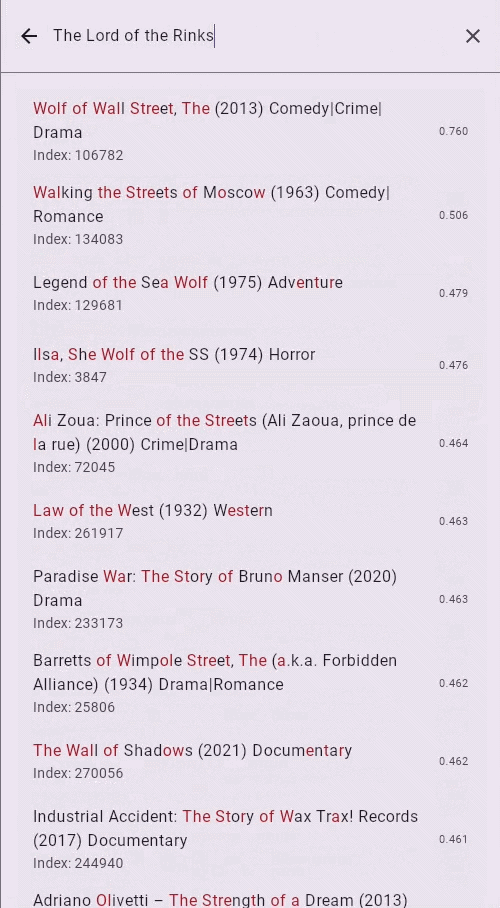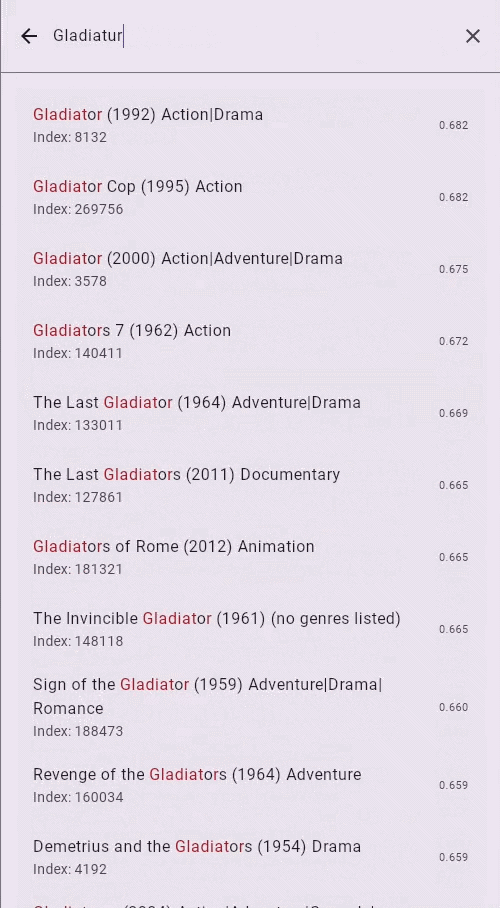
Try the Live Demo — See the engine in action. Load a dataset, start typing (even with typos), and watch results update in real time as data is still being indexed.
MutableStateFlow and PersistentMap (HAMT), allowing thousands of
concurrent reads and writes without blocking threads.Add the dependency to your build.gradle.kts in the commonMain source set:
kotlin {
sourceSets {
commonMain.dependencies {
implementation("io.github.karloti:typeahead-kmp:2.0.1") // Replace with the latest version
}
}
}typeahead-kmp is fully written in pure Kotlin with absolutely no platform-specific dependencies (like Foundation on iOS or java.util on JVM for its core logic). This allows it to be compiled and executed seamlessly across all major Kotlin Multiplatform targets:
| Category | Platform | Supported KMP Targets |
|---|---|---|
| Mobile | Android | android |
| Mobile | iOS |
iosX64, iosArm64, iosSimulatorArm64
|
| Mobile | tvOS |
tvosArm64, tvosSimulatorArm64
|
| Mobile | watchOS |
watchosArm32, watchosArm64, watchosDeviceArm64, watchosSimulatorArm64
|
| Desktop & Server | JVM | jvm |
| Desktop & Server | macOS | macosArm64 |
| Desktop & Server | Linux |
linuxX64, linuxArm64
|
| Desktop & Server | Windows | mingwX64 |
| Native Mobile | Android Native |
androidNativeArm32, androidNativeArm64, androidNativeX86, androidNativeX64
|
| Web | JavaScript | js |
| Web | WebAssembly |
wasmJs, wasmWasi
|
Because the engine manages its own memory efficiently via primitive arrays and lock-free concurrency, you will get the exact same deterministic search results and blazing-fast performance regardless of the platform you compile for.
You can initialize the engine and populate it with your dataset asynchronously. The TypeaheadSearchEngine offers several convenient factory functions (invoke operators) for initialization:
import io.github.karloti.typeahead.TypeaheadSearchEngine
import kotlinx.coroutines.flow.flowOf // For Flow-based initialization
data class Country(val id: Int, val countryName: String)
// Initialize with an Iterable (e.g., List)
val searchEngineFromList = TypeaheadSearchEngine(
items = listOf(Country(id = 1, countryName = "Canada"), Country(id = 2, countryName = "Bulgaria")),
textSelector = Country::countryName,
keySelector = Country::id // Optional, but recommended for unique identification
)
// Initialize with a Flow (for streaming data)
val searchEngineFromFlow = TypeaheadSearchEngine(
items = flowOf(Country(id = 3, countryName = "Germany"), Country(id = 4, countryName = "France")),
textSelector = Country::countryName,
keySelector = Country::id
)
// Add a single item dynamically
searchEngineFromList.add(Country(id = 999, countryName = "Mexico"))
// Add multiple items in bulk (highly optimized)
searchEngineFromList.addAll(listOf(Country(id = 5, countryName = "Japan"), Country(id = 6, countryName = "Australia")))The find() method updates the internal query, performs the search, and returns a StateFlow of ranked results.
Results are also automatically refreshed when items are added or removed while a query is active — no additional
find() call is needed.
import kotlinx.coroutines.runBlocking
runBlocking {
// 1. Perform a search — returns StateFlow<List<Pair<T, Float>>>
val resultsFlow = searchEngineFromList.find("buglaria")
// 2. Read the current results snapshot
val results = resultsFlow.value
println("Top results: $results")
// 3. Generate a character-level heatmap and render with ANSI colors
results.forEach { (country, score) ->
val heatmap = searchEngineFromList.heatmap(country.countryName) // uses the stored query
val highlighted = heatmap?.toHighlightedString() ?: country.countryName
println(" Score: ${score.toString().take(5)} | Match: $highlighted")
}
}The engine is not limited to single-word lookups. You can search with multiple words—even misspelled ones—across
documents of any length. Each query token is independently vectorized and matched against every token in the document
via cosine similarity. The per-token scores are aggregated using a Geometric Mean (penalizing partial query
coverage), multiplied by an Exponential Proximity Decay factor 1/2^(gap+1) that rewards tokens matching
adjacent positions in the document. BM25-inspired length normalization prevents long documents from unfairly
dominating short ones.
import io.github.karloti.typeahead.TypeaheadSearchEngine
data class Movie(val id: Int, val title: String, val description: String)
val engine = TypeaheadSearchEngine<Movie, Int>(
textSelector = { "${it.title} ${it.description}" },
keySelector = { it.id }
)
engine.addAll(listOf(
Movie(
id = 1,
title = "The Dark Knight",
description = "Batman raises the stakes in his war on crime in Gotham City with the help of allies Lt. Jim Gordon and DA Harvey Dent"
),
Movie(
id = 2,
title = "Interstellar",
description = "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival"),
Movie(
id = 3,
title = "The Dark Tower",
description = "A gunslinger in a dark fantasy world pursues the Man in Black across a vast desert toward a mysterious tower"),
Movie(
id = 4,
title = "Inception",
description = "A thief who steals corporate secrets through dream-sharing technology is given the inverse task of planting an idea"),
Movie(
id = 5,
title = "The Shawshank Redemption",
description = "A banker convicted of uxoricide forms a friendship over a quarter century with a hardened convict in a dark prison"),
))
// --- Single-word query ---
val results1 = engine.find("batman").value
// → #1: The Dark Knight (exact token match)
// --- Multi-word query ---
val results2 = engine.find("dark knight gotham").value
// → #1: The Dark Knight (all 3 words match adjacent positions → proximity bonus)
// → #2: The Dark Tower (shares "dark" but not "knight" or "gotham")
// --- Multi-word query with typos ---
val results3 = engine.find("drk kngiht gotam").value
// → #1: The Dark Knight (fuzzy matching recovers all 3 misspelled words)
// --- Partial recall from a long description ---
val results4 = engine.find("wormhole humanity survival").value
// → #1: Interstellar (all query words appear in the description)How multi-word scoring works:
"dark knight gotham" is tokenized into ["dark", "knight", "gotham"].1/2^(gap+1) rewards documents where matched positions are adjacent
(e.g., "dark" at position 1 and "knight" at position 2 yield maximum proximity). A BM25-inspired length
penalty ensures long documents do not unfairly dominate short ones. The final score is clamped to [0.0, 1.0].The heatmap() method uses the engine's stored query to compute a per-character match tier for any
candidate string. Each character is paired with one of four tiers:
Call toHighlightedString() on the heatmap to render it with ANSI colors for terminal output,
or map the tiers to your own UI styling (e.g., Jetpack Compose AnnotatedString, SwiftUI Text).

Visualizing the Heatmap: The heatmap pairs each character with a visual tier (exact match, N-gram block, skip-gram, or unmatched), allowing you to build beautiful, intuitive UI highlights like the one below:
Avoid recalculating vectors on the client device by pre-computing them on your backend or during the build process, then
shipping a static JSONL file. The engine supports streaming export and import using kotlinx.io and kotlinx.serialization.
import kotlinx.serialization.serializer
import kotlinx.io.buffered
import kotlinx.io.files.Path
import kotlinx.io.files.SystemFileSystem
import kotlinx.io.files.sink
// 1. Define a path for your exported data
val path = Path("typeahead_countries.jsonl")
// 2. Export the engine's internal state to a Sink (e.g., a file)
SystemFileSystem.sink(path).buffered().use { sink ->
searchEngineFromList.exportToSink(sink)
}
println("Engine state exported to $path")You can restore an engine from a Source in two ways:
A. Using the TypeaheadSearchEngine factory function (recommended for cold starts):
This method creates a new TypeaheadSearchEngine instance, reading its configuration (TypeaheadMetadata) and all pre-computed vectors directly from the source. This is the fastest way to initialize an engine.
import kotlinx.serialization.serializer
import kotlinx.io.buffered
import kotlinx.io.files.Path
import kotlinx.io.files.SystemFileSystem
import kotlinx.io.files.source
// 1. Restore the engine instantly from a Source (e.g., a file)
val restoredEngineFromFactory = TypeaheadSearchEngine(
source = SystemFileSystem.source(path).buffered(),
textSelector = Country::countryName,
keySelector = Country::id
)
println("Engine restored from factory. Size: ${restoredEngineFromFactory.size}")B. Using importFromSource() on an existing engine (for merging or overwriting):
This method imports records into an existing engine. You can choose to clearExisting data or merge the new records.
import kotlinx.serialization.serializer
import kotlinx.io.buffered
import kotlinx.io.files.Path
import kotlinx.io.files.SystemFileSystem
import kotlinx.io.files.source
// Create an empty engine or one with some initial data
val existingEngine = TypeaheadSearchEngine<Country, Int>(
textSelector = Country::countryName,
keySelector = Country::id
)
// Import from the source, clearing any existing data
SystemFileSystem.source(path).buffered().use { source ->
existingEngine.importFromSource(source)
}
println("Existing engine imported from source. Size: ${existingEngine.size}")To truly understand the power of typeahead-kmp, let's look at a real-time keystroke simulation.
Imagine a user is trying to type "Canada", but they accidentally type "Cnada" (a classic transposition error).
Here is how the engine's internal mathematical weighting dynamically reacts at each keystroke:
At this early stage, the user types C and then Cn. The P0 (First Letter) anchor heavily restricts the search
space. Because the input is extremely short, L2 Normalization naturally favors shorter words (Short-Word Bias). This
brings 4-letter countries like Cuba and Chad to the top. By the second keystroke, Canada barely enters the top 5.
=== Typing: 'C' with typing error of 'Cnada' ===
1. Cuba - Score: 0.19181583900475285
2. Chad - Score: 0.19181583900475285
3. China - Score: 0.14776063566992276
4. Chile - Score: 0.14776063566992276
5. Cyprus - Score: 0.11811359847672041
=== Typing: 'Cn' with typing error of 'Cnada' ===
1. Cuba - Score: 0.10297213760008117
2. Chad - Score: 0.10297213760008117
...
5. Canada - Score: 0.07255630308706752The user meant Can but typed Cna. A strict-prefix algorithm would drop "Canada" entirely at this exact moment. Our *
Fuzzy Prefix dynamically anchors the first letter (C) and alphabetically sorts the remaining characters (a, n).
Both the input Cna and the target Can generate the exact same spatial feature (FPR_c_an). Canada instantly
rockets to the #1 spot!
=== Typing: 'Cna' with typing error of 'Cnada' ===
1. Canada - Score: 0.14257617990546595 <-- Rockets to #1 via Fuzzy Prefix intersection!
2. Chad - Score: 0.08281542504942256
3. Cuba - Score: 0.07409801188632545
4. China - Score: 0.06757216102651037
5. Chile - Score: 0.05707958943854292The user types d. The engine momentarily switches from "Typeahead Mode" to "Spellchecker Mode" via the Typoglycemia
Gestalt Anchor. It detects a 4-letter word starting with C and ending with d. The algorithm mathematically assumes
the user is actively trying to spell Chad and applies a massive 15.0 spatial intersection multiplier to that specific
vector, temporarily overtaking Canada.
=== Typing: 'Cnad' with typing error of 'Cnada' ===
1. Chad - Score: 0.1853988462303561 <-- Massive spike due to Gestalt anchor (C...d)!
2. Canada - Score: 0.1278792484954006
3. Cuba - Score: 0.07957032027053908
4. China - Score: 0.04934251382749997
5. Chile - Score: 0.04168063279838507The final a is typed (length 5). The Gestalt anchor for Chad (length 4) completely breaks. The engine reverts to
deep structural analysis. Overlapping Skip-Grams seamlessly bridge the transposed letters (C-n-a-d-a). This structural
skeleton perfectly aligns with the core features of Canada, accumulating a massive dot-product score that completely
overcomes the length penalty. Canada firmly reclaims the #1 spot!
=== Typing: 'Cnada' with typing error of 'Cnada' ===
1. Canada - Score: 0.2563201621199545 <-- Reclaims the lead via deep structural sequence momentum!
2. China - Score: 0.10623856459894943
3. Chad - Score: 0.05424611768613351
4. Grenada - Score: 0.04955129623022677
5. Chile - Score: 0.047217139821755294This dynamic, keystroke-by-keystroke shifting between prefix-matching, gestalt spellchecking, and sequence
momentum—all happening without memory allocations—is what makes typeahead-kmp uniquely powerful for
human-driven inputs.

This dynamic, keystroke-by-keystroke shifting between prefix-matching, gestalt spellchecking, and sequence momentum—all happening without memory allocations—is what makes this engine uniquely powerful.
Real users don't just search for single words. When looking for a movie, a product, or a record in a large dataset,
they often type fragments of multiple words—frequently with typos. typeahead-kmp handles this natively.
Imagine you have indexed thousands of movies with their full descriptions. A user wants to find
"Harry Potter and the Goblet of Fire" but types: hariy pota gobelt
=== Results for sloppy query: [hariy pota gobelt] ===
1. Score: 0.347 | Harry Potter and the Goblet of Fire is a brilliant fantasy movie released in 2005.
2. Score: 0.213 | A completely unrelated movie where a magical goblet was found in the fire.
3. Score: 0.208 | Harry Potter and the Chamber of Secrets is also a great fantasy movie about wizards.Why it works:
hariy fuzzy-matches harry (transposed r/i) via shared n-grams and skip-gramspota fuzzy-matches potter (truncated suffix) via fuzzy prefix anchoringgobelt fuzzy-matches goblet (transposed e/l) via n-gram overlap1/2^(gap+1) yields maximum proximity for consecutive tokens)goblet) is penalized for partial coveragegoblet and fire but not harry or potter—the harmonic mean drives its score near zeroEven when every word in the query contains errors, the engine recovers:
Query: "fsat brwon fxo" (intended: "fast brown fox")
1. Score: 0.606 | The really fast brown fox jumps over the lazy dog. ← Proximity decay maximized!
2. Score: 0.416 | The fox is very fast but the brown bear is slow. ← All words present, scattered
3. Score: 0.275 | The fast rabbit jumps over the deep brown forest. ← Missing "fox"
The exponential proximity decay gives the first document a clear lead because fast, brown, and fox appear
at consecutive positions—yielding a proximity ratio of 1.0—even though all three query tokens were misspelled.
While typeahead-kmp is heavily optimized for real-time mobile and web UIs, its underlying L2-normalized sparse vector
engine is highly versatile and can be applied to backend utilities and Command Line Interfaces (CLIs).
Included in the repository is a practical example of a CLI Fuzzy File Search. When navigating deeply nested directory structures, it is incredibly common to mistype a filename. Instead of a frustrating "File not found" error, this tool leverages the typeahead engine to act as a resilient safety net, instantly suggesting the closest possible matches.

.git), feeding file names into the TypeaheadSearchEngine while storing their absolute paths as the associated
payload.Typeahed
instead of Typeahead), the exact search fails, and the engine immediately falls back to its vector space search to
find the nearest neighbors.heatmap() API.
After calling find(), the engine stores the query internally. Calling heatmap(text) computes a per-character
match tier list, and toHighlightedString() renders it with ANSI colors for terminal output:This demonstrates how the internal scoring mechanism can be directly piped into UI rendering logic—whether that's a terminal output or styled text in Jetpack Compose / SwiftUI.
Building a perfect typeahead engine is notoriously difficult. During the development of this library, we evaluated and discarded several standard approaches because they fundamentally misalign with human typing behavior.
While engines like Algolia and Typesense are industry standards for massive databases, they require network
requests. In mobile or web front-ends, network latency kills the instant "typeahead" feel. typeahead-kmp brings
vector-search intelligence directly to the client.
Building a perfect typeahead engine requires balancing real-time UI performance with human typing psychology. During the development of this library, we evaluated, implemented, and ultimately discarded several standard algorithmic approaches because they fundamentally misalign with the constraints of mobile environments (60fps UI rendering, memory fragmentation, Garbage Collection pauses) or human behavior.
Strict Prefix Tries / Radix Trees: Extremely fast (O(L) where L is query length) and highly memory-efficient.
However, they offer absolutely zero typo tolerance. A single transposed or missed character instantly shatters the
search path, frustrating users who type quickly on glass screens.
Levenshtein & Damerau-Levenshtein Distance: The industry standard for spelling correction. Unfortunately, these
operate with O(N*M) time complexity via dynamic programming matrices. Running this math across thousands of records
on every single keystroke quickly blocks the Main UI thread on mobile devices, causing frame drops and stuttering.
Furthermore, they heavily penalize string length differences and fail completely at the "Blind Continuation"
phenomenon (where an early typo derails the entire score, even if the rest of the word is typed perfectly).
Jaro-Winkler Similarity: Specifically designed to give heavy weight to matching prefixes, making it seemingly
ideal for autocomplete. However, it still suffers from O(N*M) CPU bottlenecks. More importantly, its strict prefix
anchor means that if the user makes a mistake in the very first or second character, the similarity score degrades
drastically, destroying the typeahead experience.
Weighted Longest Common Subsequence (LCS): While applying index-based positional weights to an LCS algorithm improves accuracy for scattered keystrokes and dropped characters, it still requires complex matrix backtracking. This mathematical overhead is simply too slow for asynchronous, per-keystroke rendering.
Standard N-Grams & Jaccard / Cosine Sets: Breaking strings into overlapping chunks (N-grams) solves the typo and
transposition problems beautifully. However, traditional implementations rely heavily on creating massive amounts of
intermediate String objects or Set collections. On mobile (JVM/ART or Kotlin Native), this triggers aggressive
Garbage Collection (GC) pauses, leading to UI jitter. Additionally, standard sets treat words as bags-of-tokens,
completely losing the critical "Prefix Anchor" (the fact that the beginning of a word matters more than the end).
They also lack native multi-word support—a query like "dark knight gotham" must be manually split and scored
word-by-word with no positional awareness of how query words relate to each other within the document.
Ratcliff-Obershelp & SIFT4: While experimental algorithms like SIFT4 simulate human perception and operate in
linear time (O(max(N,M))), they lack the structural optimizations required for concurrent environments. They don't
natively integrate with lock-free data structures, making them difficult to scale across highly concurrent
reader/writer coroutines without blocking.
In-Memory Dense Vector Databases: Using traditional dense embeddings (like standard AI vector DBs) provides
excellent semantic and fuzzy matching (O(log N) search times). However, the memory footprint is massive. Inserting,
updating, and holding full dense vectors in RAM is computationally expensive and battery-draining, making them
absolute overkill for purely syntactic typeahead.
To solve these compounding issues, typeahead-kmp abandons traditional string-to-string comparisons during the search
phase.
Instead, it functions as a highly specialized, local vector database:
FloatArray structures, strictly halving memory footprints and completely eliminating object fragmentation
and GC pauses.O(1) candidate
retrieval per vocabulary term—only relevant documents are scored, not the entire dataset. Stage 2 re-computes full
cosine similarity between each query token and every document token, then aggregates via harmonic mean with
exponential proximity decay 1/2^(gap+1) and BM25-inspired length normalization."dark knight" naturally scores higher against "...the dark knight rises..." than against a document with "dark" and "knight" scattered far apart.PersistentMap) and atomic Compare-And-Swap (CAS) operations
via a custom ConcurrentPriorityQueue, the engine handles thousands of parallel reads and writes without ever
locking a thread.[0.0, 1.0] in milliseconds.| Algorithm | Typo Tolerance | Prefix Anchor | Multi-Word | Memory Cost | Blind Continuation | Search Complexity |
|---|---|---|---|---|---|---|
| Strict Prefix Tries | ❌ None | ✅ Perfect | ❌ None | ✅ Low | ❌ Fails | O(L) |
| Levenshtein Distance | ✅ Good | ❌ Poor | ❌ None | ✅ Low | ❌ Poor |
O(N·M) per pair |
| Weighted & Damerau-Levenshtein | ✅ Excellent | ❌ Poor | ❌ None | ❌ Poor |
O(N·M) per pair |
|
| Jaro-Winkler | ✅ Good | ✅ Excellent | ❌ None | ✅ Low | ❌ Poor |
O(N·M) per pair |
| Longest Common Subsequence (LCS) | ✅ Good | ❌ None |
O(N·M) per pair |
|||
| Standard N-Grams & Q-Grams | ✅ Good | ❌ Poor | ✅ Good |
O(N+M) per pair |
||
| Cosine / Jaccard / Dice (Sets) | ✅ Good | ❌ Poor | ✅ Good |
O(N+M) per pair |
||
| Ratcliff-Obershelp | ❌ Poor | ❌ None |
O(N³) worst case |
|||
| SIFT4 (Experimental) | ✅ Excellent | ❌ None | ✅ Low | ✅ Good |
O(max(N,M)) per pair |
|
| Dense Vector DBs | ✅ Excellent | ❌ Poor | ✅ Native | ❌ Massive | ✅ Excellent |
O(D·N) or O(D·log N) with ANN |
| Typeahead KMP (Ours) | ✅ Excellent | ✅ Excellent | ✅ Native | ✅ Low (Sparse) | ✅ Excellent | O(Q·K·D_t) |
Complexity legend for Typeahead KMP:
Q = number of query tokens (words in the search phrase)K = number of non-zero overlapping features per token pair (bounded by n-gram size, typically ≤ 30)D_t = number of tokens in the candidate documentO(1) per vocabulary term), so only relevant documents are scored—not the entire dataset. For typical typeahead workloads (short queries, bounded result sets), search time is effectively constant relative to total dataset size.The engine is engineered for environments with strict memory and CPU constraints:
FloatArray and IntArray) internally instead of object
wrappers, cutting memory footprint by more than 50%.ConcurrentPriorityQueue that discards low-priority matches
instantly without allocation.MutableStateFlow and Kotlin's PersistentMap. This
ensures that even if you hammer the engine with 10,000 concurrent .add() operations, no data is lost and the thread
is never blocked.To demonstrate the engine's efficiency under heavy loads, we run an aggressive benchmark indexing 10,000 complex product records (resulting in an 84 MB JSON export).
Because string tokenization and mathematical L2-normalization are computationally heavy, the initial insertion takes some CPU time and memory. However, importing pre-computed vectors bypasses all mathematical operations, resulting in a near-instant cold-start with virtually zero memory bloat.
================================================================================
PERFORMANCE SUMMARY (10,000 Records)
================================================================================
Insertion: 419 ms | Memory: 114 MB <-- Heavy mathematical tokenization
Export: 7 ms | Memory: 1 MB <-- Instant state read via PersistentMap
Serialization: 432 ms
File Write: 117 ms | Disk: 84 MB
File Read: 108 ms
Deserialization: 428 ms | Memory: 192 MB
Import (Restore): 9 ms | Memory: 5 MB <-- Bypasses math; instant state hydration!
================================================================================
Total Time: 1520 ms
================================================================================
✅ Import verification completed successfully - all results are identical!7 ms because the internal PersistentMap allows instant
iteration without locking the data structure.9 ms and 5 MB of RAM. By generating the JSON
index on your backend or during CI/CD, you can ship it to mobile clients for instant search availability on app
launch.We use YouTrack for task management and issue tracking. You can view the current tasks and progress here: Typeahead KMP Issues & Roadmap
This project is licensed under the Apache License Version 2.0 - see the LICENSE file for details.
A high-performance, asynchronous, and lock-free in-memory fuzzy search engine designed specifically for Kotlin Multiplatform (KMP).
Unlike standard search algorithms that fail during real-time typing, typeahead-kmp is built to understand the "Blind
Continuation" phenomenon—where users make an early typo but intuitively continue typing the rest of the word
correctly. It also supports multi-word queries across documents of any length—from short labels to long
descriptions—using a tokenized two-stage retrieval architecture with Geometric Mean Scoring, Exponential Proximity
Decay for adjacency awareness, and BM25-inspired length normalization.
Powered by a custom L2-Normalized Sparse Vector Space algorithm, a Flyweight Vocabulary Cache, an Inverted
Index, and immutable state management, it acts as a highly optimized, local vector database. Each query token is
independently matched against the vocabulary and scored against every document token, so searching for "dark knight"
across thousands of movie descriptions works just as naturally as searching for a single word like "batman". The engine
yields a normalized similarity score in [0.0, 1.0] while gracefully handling skipped characters, swapped letters,
and phonetic typos.
Try the Live Demo — See the engine in action. Load a dataset, start typing (even with typos), and watch results update in real time as data is still being indexed.
MutableStateFlow and PersistentMap (HAMT), allowing thousands of
concurrent reads and writes without blocking threads.Add the dependency to your build.gradle.kts in the commonMain source set:
kotlin {
sourceSets {
commonMain.dependencies {
implementation("io.github.karloti:typeahead-kmp:2.0.1") // Replace with the latest version
}
}
}typeahead-kmp is fully written in pure Kotlin with absolutely no platform-specific dependencies (like Foundation on iOS or java.util on JVM for its core logic). This allows it to be compiled and executed seamlessly across all major Kotlin Multiplatform targets:
| Category | Platform | Supported KMP Targets |
|---|---|---|
| Mobile | Android | android |
| Mobile | iOS |
iosX64, iosArm64, iosSimulatorArm64
|
| Mobile | tvOS |
tvosArm64, tvosSimulatorArm64
|
| Mobile | watchOS |
watchosArm32, watchosArm64, watchosDeviceArm64, watchosSimulatorArm64
|
| Desktop & Server | JVM | jvm |
| Desktop & Server | macOS | macosArm64 |
| Desktop & Server | Linux |
linuxX64, linuxArm64
|
| Desktop & Server | Windows | mingwX64 |
| Native Mobile | Android Native |
androidNativeArm32, androidNativeArm64, androidNativeX86, androidNativeX64
|
| Web | JavaScript | js |
| Web | WebAssembly |
wasmJs, wasmWasi
|
Because the engine manages its own memory efficiently via primitive arrays and lock-free concurrency, you will get the exact same deterministic search results and blazing-fast performance regardless of the platform you compile for.
You can initialize the engine and populate it with your dataset asynchronously. The TypeaheadSearchEngine offers several convenient factory functions (invoke operators) for initialization:
import io.github.karloti.typeahead.TypeaheadSearchEngine
import kotlinx.coroutines.flow.flowOf // For Flow-based initialization
data class Country(val id: Int, val countryName: String)
// Initialize with an Iterable (e.g., List)
val searchEngineFromList = TypeaheadSearchEngine(
items = listOf(Country(id = 1, countryName = "Canada"), Country(id = 2, countryName = "Bulgaria")),
textSelector = Country::countryName,
keySelector = Country::id // Optional, but recommended for unique identification
)
// Initialize with a Flow (for streaming data)
val searchEngineFromFlow = TypeaheadSearchEngine(
items = flowOf(Country(id = 3, countryName = "Germany"), Country(id = 4, countryName = "France")),
textSelector = Country::countryName,
keySelector = Country::id
)
// Add a single item dynamically
searchEngineFromList.add(Country(id = 999, countryName = "Mexico"))
// Add multiple items in bulk (highly optimized)
searchEngineFromList.addAll(listOf(Country(id = 5, countryName = "Japan"), Country(id = 6, countryName = "Australia")))The find() method updates the internal query, performs the search, and returns a StateFlow of ranked results.
Results are also automatically refreshed when items are added or removed while a query is active — no additional
find() call is needed.
import kotlinx.coroutines.runBlocking
runBlocking {
// 1. Perform a search — returns StateFlow<List<Pair<T, Float>>>
val resultsFlow = searchEngineFromList.find("buglaria")
// 2. Read the current results snapshot
val results = resultsFlow.value
println("Top results: $results")
// 3. Generate a character-level heatmap and render with ANSI colors
results.forEach { (country, score) ->
val heatmap = searchEngineFromList.heatmap(country.countryName) // uses the stored query
val highlighted = heatmap?.toHighlightedString() ?: country.countryName
println(" Score: ${score.toString().take(5)} | Match: $highlighted")
}
}The engine is not limited to single-word lookups. You can search with multiple words—even misspelled ones—across
documents of any length. Each query token is independently vectorized and matched against every token in the document
via cosine similarity. The per-token scores are aggregated using a Geometric Mean (penalizing partial query
coverage), multiplied by an Exponential Proximity Decay factor 1/2^(gap+1) that rewards tokens matching
adjacent positions in the document. BM25-inspired length normalization prevents long documents from unfairly
dominating short ones.
import io.github.karloti.typeahead.TypeaheadSearchEngine
data class Movie(val id: Int, val title: String, val description: String)
val engine = TypeaheadSearchEngine<Movie, Int>(
textSelector = { "${it.title} ${it.description}" },
keySelector = { it.id }
)
engine.addAll(listOf(
Movie(
id = 1,
title = "The Dark Knight",
description = "Batman raises the stakes in his war on crime in Gotham City with the help of allies Lt. Jim Gordon and DA Harvey Dent"
),
Movie(
id = 2,
title = "Interstellar",
description = "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival"),
Movie(
id = 3,
title = "The Dark Tower",
description = "A gunslinger in a dark fantasy world pursues the Man in Black across a vast desert toward a mysterious tower"),
Movie(
id = 4,
title = "Inception",
description = "A thief who steals corporate secrets through dream-sharing technology is given the inverse task of planting an idea"),
Movie(
id = 5,
title = "The Shawshank Redemption",
description = "A banker convicted of uxoricide forms a friendship over a quarter century with a hardened convict in a dark prison"),
))
// --- Single-word query ---
val results1 = engine.find("batman").value
// → #1: The Dark Knight (exact token match)
// --- Multi-word query ---
val results2 = engine.find("dark knight gotham").value
// → #1: The Dark Knight (all 3 words match adjacent positions → proximity bonus)
// → #2: The Dark Tower (shares "dark" but not "knight" or "gotham")
// --- Multi-word query with typos ---
val results3 = engine.find("drk kngiht gotam").value
// → #1: The Dark Knight (fuzzy matching recovers all 3 misspelled words)
// --- Partial recall from a long description ---
val results4 = engine.find("wormhole humanity survival").value
// → #1: Interstellar (all query words appear in the description)How multi-word scoring works:
"dark knight gotham" is tokenized into ["dark", "knight", "gotham"].1/2^(gap+1) rewards documents where matched positions are adjacent
(e.g., "dark" at position 1 and "knight" at position 2 yield maximum proximity). A BM25-inspired length
penalty ensures long documents do not unfairly dominate short ones. The final score is clamped to [0.0, 1.0].The heatmap() method uses the engine's stored query to compute a per-character match tier for any
candidate string. Each character is paired with one of four tiers:
Call toHighlightedString() on the heatmap to render it with ANSI colors for terminal output,
or map the tiers to your own UI styling (e.g., Jetpack Compose AnnotatedString, SwiftUI Text).
Visualizing the Heatmap: The heatmap pairs each character with a visual tier (exact match, N-gram block, skip-gram, or unmatched), allowing you to build beautiful, intuitive UI highlights like the one below:
Avoid recalculating vectors on the client device by pre-computing them on your backend or during the build process, then
shipping a static JSONL file. The engine supports streaming export and import using kotlinx.io and kotlinx.serialization.
import kotlinx.serialization.serializer
import kotlinx.io.buffered
import kotlinx.io.files.Path
import kotlinx.io.files.SystemFileSystem
import kotlinx.io.files.sink
// 1. Define a path for your exported data
val path = Path("typeahead_countries.jsonl")
// 2. Export the engine's internal state to a Sink (e.g., a file)
SystemFileSystem.sink(path).buffered().use { sink ->
searchEngineFromList.exportToSink(sink)
}
println("Engine state exported to $path")You can restore an engine from a Source in two ways:
A. Using the TypeaheadSearchEngine factory function (recommended for cold starts):
This method creates a new TypeaheadSearchEngine instance, reading its configuration (TypeaheadMetadata) and all pre-computed vectors directly from the source. This is the fastest way to initialize an engine.
import kotlinx.serialization.serializer
import kotlinx.io.buffered
import kotlinx.io.files.Path
import kotlinx.io.files.SystemFileSystem
import kotlinx.io.files.source
// 1. Restore the engine instantly from a Source (e.g., a file)
val restoredEngineFromFactory = TypeaheadSearchEngine(
source = SystemFileSystem.source(path).buffered(),
textSelector = Country::countryName,
keySelector = Country::id
)
println("Engine restored from factory. Size: ${restoredEngineFromFactory.size}")B. Using importFromSource() on an existing engine (for merging or overwriting):
This method imports records into an existing engine. You can choose to clearExisting data or merge the new records.
import kotlinx.serialization.serializer
import kotlinx.io.buffered
import kotlinx.io.files.Path
import kotlinx.io.files.SystemFileSystem
import kotlinx.io.files.source
// Create an empty engine or one with some initial data
val existingEngine = TypeaheadSearchEngine<Country, Int>(
textSelector = Country::countryName,
keySelector = Country::id
)
// Import from the source, clearing any existing data
SystemFileSystem.source(path).buffered().use { source ->
existingEngine.importFromSource(source)
}
println("Existing engine imported from source. Size: ${existingEngine.size}")To truly understand the power of typeahead-kmp, let's look at a real-time keystroke simulation.
Imagine a user is trying to type "Canada", but they accidentally type "Cnada" (a classic transposition error).
Here is how the engine's internal mathematical weighting dynamically reacts at each keystroke:
At this early stage, the user types C and then Cn. The P0 (First Letter) anchor heavily restricts the search
space. Because the input is extremely short, L2 Normalization naturally favors shorter words (Short-Word Bias). This
brings 4-letter countries like Cuba and Chad to the top. By the second keystroke, Canada barely enters the top 5.
=== Typing: 'C' with typing error of 'Cnada' ===
1. Cuba - Score: 0.19181583900475285
2. Chad - Score: 0.19181583900475285
3. China - Score: 0.14776063566992276
4. Chile - Score: 0.14776063566992276
5. Cyprus - Score: 0.11811359847672041
=== Typing: 'Cn' with typing error of 'Cnada' ===
1. Cuba - Score: 0.10297213760008117
2. Chad - Score: 0.10297213760008117
...
5. Canada - Score: 0.07255630308706752The user meant Can but typed Cna. A strict-prefix algorithm would drop "Canada" entirely at this exact moment. Our *
Fuzzy Prefix dynamically anchors the first letter (C) and alphabetically sorts the remaining characters (a, n).
Both the input Cna and the target Can generate the exact same spatial feature (FPR_c_an). Canada instantly
rockets to the #1 spot!
=== Typing: 'Cna' with typing error of 'Cnada' ===
1. Canada - Score: 0.14257617990546595 <-- Rockets to #1 via Fuzzy Prefix intersection!
2. Chad - Score: 0.08281542504942256
3. Cuba - Score: 0.07409801188632545
4. China - Score: 0.06757216102651037
5. Chile - Score: 0.05707958943854292The user types d. The engine momentarily switches from "Typeahead Mode" to "Spellchecker Mode" via the Typoglycemia
Gestalt Anchor. It detects a 4-letter word starting with C and ending with d. The algorithm mathematically assumes
the user is actively trying to spell Chad and applies a massive 15.0 spatial intersection multiplier to that specific
vector, temporarily overtaking Canada.
=== Typing: 'Cnad' with typing error of 'Cnada' ===
1. Chad - Score: 0.1853988462303561 <-- Massive spike due to Gestalt anchor (C...d)!
2. Canada - Score: 0.1278792484954006
3. Cuba - Score: 0.07957032027053908
4. China - Score: 0.04934251382749997
5. Chile - Score: 0.04168063279838507The final a is typed (length 5). The Gestalt anchor for Chad (length 4) completely breaks. The engine reverts to
deep structural analysis. Overlapping Skip-Grams seamlessly bridge the transposed letters (C-n-a-d-a). This structural
skeleton perfectly aligns with the core features of Canada, accumulating a massive dot-product score that completely
overcomes the length penalty. Canada firmly reclaims the #1 spot!
=== Typing: 'Cnada' with typing error of 'Cnada' ===
1. Canada - Score: 0.2563201621199545 <-- Reclaims the lead via deep structural sequence momentum!
2. China - Score: 0.10623856459894943
3. Chad - Score: 0.05424611768613351
4. Grenada - Score: 0.04955129623022677
5. Chile - Score: 0.047217139821755294This dynamic, keystroke-by-keystroke shifting between prefix-matching, gestalt spellchecking, and sequence
momentum—all happening without memory allocations—is what makes typeahead-kmp uniquely powerful for
human-driven inputs.
This dynamic, keystroke-by-keystroke shifting between prefix-matching, gestalt spellchecking, and sequence momentum—all happening without memory allocations—is what makes this engine uniquely powerful.
Real users don't just search for single words. When looking for a movie, a product, or a record in a large dataset,
they often type fragments of multiple words—frequently with typos. typeahead-kmp handles this natively.
Imagine you have indexed thousands of movies with their full descriptions. A user wants to find
"Harry Potter and the Goblet of Fire" but types: hariy pota gobelt
=== Results for sloppy query: [hariy pota gobelt] ===
1. Score: 0.347 | Harry Potter and the Goblet of Fire is a brilliant fantasy movie released in 2005.
2. Score: 0.213 | A completely unrelated movie where a magical goblet was found in the fire.
3. Score: 0.208 | Harry Potter and the Chamber of Secrets is also a great fantasy movie about wizards.Why it works:
hariy fuzzy-matches harry (transposed r/i) via shared n-grams and skip-gramspota fuzzy-matches potter (truncated suffix) via fuzzy prefix anchoringgobelt fuzzy-matches goblet (transposed e/l) via n-gram overlap1/2^(gap+1) yields maximum proximity for consecutive tokens)goblet) is penalized for partial coveragegoblet and fire but not harry or potter—the harmonic mean drives its score near zeroEven when every word in the query contains errors, the engine recovers:
Query: "fsat brwon fxo" (intended: "fast brown fox")
1. Score: 0.606 | The really fast brown fox jumps over the lazy dog. ← Proximity decay maximized!
2. Score: 0.416 | The fox is very fast but the brown bear is slow. ← All words present, scattered
3. Score: 0.275 | The fast rabbit jumps over the deep brown forest. ← Missing "fox"
The exponential proximity decay gives the first document a clear lead because fast, brown, and fox appear
at consecutive positions—yielding a proximity ratio of 1.0—even though all three query tokens were misspelled.
While typeahead-kmp is heavily optimized for real-time mobile and web UIs, its underlying L2-normalized sparse vector
engine is highly versatile and can be applied to backend utilities and Command Line Interfaces (CLIs).
Included in the repository is a practical example of a CLI Fuzzy File Search. When navigating deeply nested directory structures, it is incredibly common to mistype a filename. Instead of a frustrating "File not found" error, this tool leverages the typeahead engine to act as a resilient safety net, instantly suggesting the closest possible matches.
.git), feeding file names into the TypeaheadSearchEngine while storing their absolute paths as the associated
payload.Typeahed
instead of Typeahead), the exact search fails, and the engine immediately falls back to its vector space search to
find the nearest neighbors.heatmap() API.
After calling find(), the engine stores the query internally. Calling heatmap(text) computes a per-character
match tier list, and toHighlightedString() renders it with ANSI colors for terminal output:This demonstrates how the internal scoring mechanism can be directly piped into UI rendering logic—whether that's a terminal output or styled text in Jetpack Compose / SwiftUI.
Building a perfect typeahead engine is notoriously difficult. During the development of this library, we evaluated and discarded several standard approaches because they fundamentally misalign with human typing behavior.
While engines like Algolia and Typesense are industry standards for massive databases, they require network
requests. In mobile or web front-ends, network latency kills the instant "typeahead" feel. typeahead-kmp brings
vector-search intelligence directly to the client.
Building a perfect typeahead engine requires balancing real-time UI performance with human typing psychology. During the development of this library, we evaluated, implemented, and ultimately discarded several standard algorithmic approaches because they fundamentally misalign with the constraints of mobile environments (60fps UI rendering, memory fragmentation, Garbage Collection pauses) or human behavior.
Strict Prefix Tries / Radix Trees: Extremely fast (O(L) where L is query length) and highly memory-efficient.
However, they offer absolutely zero typo tolerance. A single transposed or missed character instantly shatters the
search path, frustrating users who type quickly on glass screens.
Levenshtein & Damerau-Levenshtein Distance: The industry standard for spelling correction. Unfortunately, these
operate with O(N*M) time complexity via dynamic programming matrices. Running this math across thousands of records
on every single keystroke quickly blocks the Main UI thread on mobile devices, causing frame drops and stuttering.
Furthermore, they heavily penalize string length differences and fail completely at the "Blind Continuation"
phenomenon (where an early typo derails the entire score, even if the rest of the word is typed perfectly).
Jaro-Winkler Similarity: Specifically designed to give heavy weight to matching prefixes, making it seemingly
ideal for autocomplete. However, it still suffers from O(N*M) CPU bottlenecks. More importantly, its strict prefix
anchor means that if the user makes a mistake in the very first or second character, the similarity score degrades
drastically, destroying the typeahead experience.
Weighted Longest Common Subsequence (LCS): While applying index-based positional weights to an LCS algorithm improves accuracy for scattered keystrokes and dropped characters, it still requires complex matrix backtracking. This mathematical overhead is simply too slow for asynchronous, per-keystroke rendering.
Standard N-Grams & Jaccard / Cosine Sets: Breaking strings into overlapping chunks (N-grams) solves the typo and
transposition problems beautifully. However, traditional implementations rely heavily on creating massive amounts of
intermediate String objects or Set collections. On mobile (JVM/ART or Kotlin Native), this triggers aggressive
Garbage Collection (GC) pauses, leading to UI jitter. Additionally, standard sets treat words as bags-of-tokens,
completely losing the critical "Prefix Anchor" (the fact that the beginning of a word matters more than the end).
They also lack native multi-word support—a query like "dark knight gotham" must be manually split and scored
word-by-word with no positional awareness of how query words relate to each other within the document.
Ratcliff-Obershelp & SIFT4: While experimental algorithms like SIFT4 simulate human perception and operate in
linear time (O(max(N,M))), they lack the structural optimizations required for concurrent environments. They don't
natively integrate with lock-free data structures, making them difficult to scale across highly concurrent
reader/writer coroutines without blocking.
In-Memory Dense Vector Databases: Using traditional dense embeddings (like standard AI vector DBs) provides
excellent semantic and fuzzy matching (O(log N) search times). However, the memory footprint is massive. Inserting,
updating, and holding full dense vectors in RAM is computationally expensive and battery-draining, making them
absolute overkill for purely syntactic typeahead.
To solve these compounding issues, typeahead-kmp abandons traditional string-to-string comparisons during the search
phase.
Instead, it functions as a highly specialized, local vector database:
FloatArray structures, strictly halving memory footprints and completely eliminating object fragmentation
and GC pauses.O(1) candidate
retrieval per vocabulary term—only relevant documents are scored, not the entire dataset. Stage 2 re-computes full
cosine similarity between each query token and every document token, then aggregates via harmonic mean with
exponential proximity decay 1/2^(gap+1) and BM25-inspired length normalization."dark knight" naturally scores higher against "...the dark knight rises..." than against a document with "dark" and "knight" scattered far apart.PersistentMap) and atomic Compare-And-Swap (CAS) operations
via a custom ConcurrentPriorityQueue, the engine handles thousands of parallel reads and writes without ever
locking a thread.[0.0, 1.0] in milliseconds.| Algorithm | Typo Tolerance | Prefix Anchor | Multi-Word | Memory Cost | Blind Continuation | Search Complexity |
|---|---|---|---|---|---|---|
| Strict Prefix Tries | ❌ None | ✅ Perfect | ❌ None | ✅ Low | ❌ Fails | O(L) |
| Levenshtein Distance | ✅ Good | ❌ Poor | ❌ None | ✅ Low | ❌ Poor |
O(N·M) per pair |
| Weighted & Damerau-Levenshtein | ✅ Excellent | ❌ Poor | ❌ None | ❌ Poor |
O(N·M) per pair |
|
| Jaro-Winkler | ✅ Good | ✅ Excellent | ❌ None | ✅ Low | ❌ Poor |
O(N·M) per pair |
| Longest Common Subsequence (LCS) | ✅ Good | ❌ None |
O(N·M) per pair |
|||
| Standard N-Grams & Q-Grams | ✅ Good | ❌ Poor | ✅ Good |
O(N+M) per pair |
||
| Cosine / Jaccard / Dice (Sets) | ✅ Good | ❌ Poor | ✅ Good |
O(N+M) per pair |
||
| Ratcliff-Obershelp | ❌ Poor | ❌ None |
O(N³) worst case |
|||
| SIFT4 (Experimental) | ✅ Excellent | ❌ None | ✅ Low | ✅ Good |
O(max(N,M)) per pair |
|
| Dense Vector DBs | ✅ Excellent | ❌ Poor | ✅ Native | ❌ Massive | ✅ Excellent |
O(D·N) or O(D·log N) with ANN |
| Typeahead KMP (Ours) | ✅ Excellent | ✅ Excellent | ✅ Native | ✅ Low (Sparse) | ✅ Excellent | O(Q·K·D_t) |
Complexity legend for Typeahead KMP:
Q = number of query tokens (words in the search phrase)K = number of non-zero overlapping features per token pair (bounded by n-gram size, typically ≤ 30)D_t = number of tokens in the candidate documentO(1) per vocabulary term), so only relevant documents are scored—not the entire dataset. For typical typeahead workloads (short queries, bounded result sets), search time is effectively constant relative to total dataset size.The engine is engineered for environments with strict memory and CPU constraints:
FloatArray and IntArray) internally instead of object
wrappers, cutting memory footprint by more than 50%.ConcurrentPriorityQueue that discards low-priority matches
instantly without allocation.MutableStateFlow and Kotlin's PersistentMap. This
ensures that even if you hammer the engine with 10,000 concurrent .add() operations, no data is lost and the thread
is never blocked.To demonstrate the engine's efficiency under heavy loads, we run an aggressive benchmark indexing 10,000 complex product records (resulting in an 84 MB JSON export).
Because string tokenization and mathematical L2-normalization are computationally heavy, the initial insertion takes some CPU time and memory. However, importing pre-computed vectors bypasses all mathematical operations, resulting in a near-instant cold-start with virtually zero memory bloat.
================================================================================
PERFORMANCE SUMMARY (10,000 Records)
================================================================================
Insertion: 419 ms | Memory: 114 MB <-- Heavy mathematical tokenization
Export: 7 ms | Memory: 1 MB <-- Instant state read via PersistentMap
Serialization: 432 ms
File Write: 117 ms | Disk: 84 MB
File Read: 108 ms
Deserialization: 428 ms | Memory: 192 MB
Import (Restore): 9 ms | Memory: 5 MB <-- Bypasses math; instant state hydration!
================================================================================
Total Time: 1520 ms
================================================================================
✅ Import verification completed successfully - all results are identical!7 ms because the internal PersistentMap allows instant
iteration without locking the data structure.9 ms and 5 MB of RAM. By generating the JSON
index on your backend or during CI/CD, you can ship it to mobile clients for instant search availability on app
launch.We use YouTrack for task management and issue tracking. You can view the current tasks and progress here: Typeahead KMP Issues & Roadmap
This project is licensed under the Apache License Version 2.0 - see the LICENSE file for details.